Design for failure
Unless you're running Elasticsearch on a single node, prepare to design for failure. Designing for failure means running your cluster in multiple locations and be ready to lose a whole data center without service interruption. It's not theoretical thinking here. You WILL lose a whole data center several times during your cluster's life.
Elasticsearch nodes come under 4 flavors:
- (Eligible) master nodes: controls the cluster.
- Http nodes: to run your queries to.
- Data nodes: the place data is stored, obviously.
- Coordinating nodes: see them as smart load balancers.
The minimum requirement for a fault tolerant cluster is:
- 3 locations to host your nodes. 2 locations to run half of your cluster, and one for the backup master node.
- 3 master nodes. You need an odd number of eligible master nodes to avoid split brains when you lose a whole data center. Put one master node in each location so you hopefully never lose the quorum.
- 2 http nodes, one in each primary data center.
- As many data nodes as you need, split evenly between both main locations.
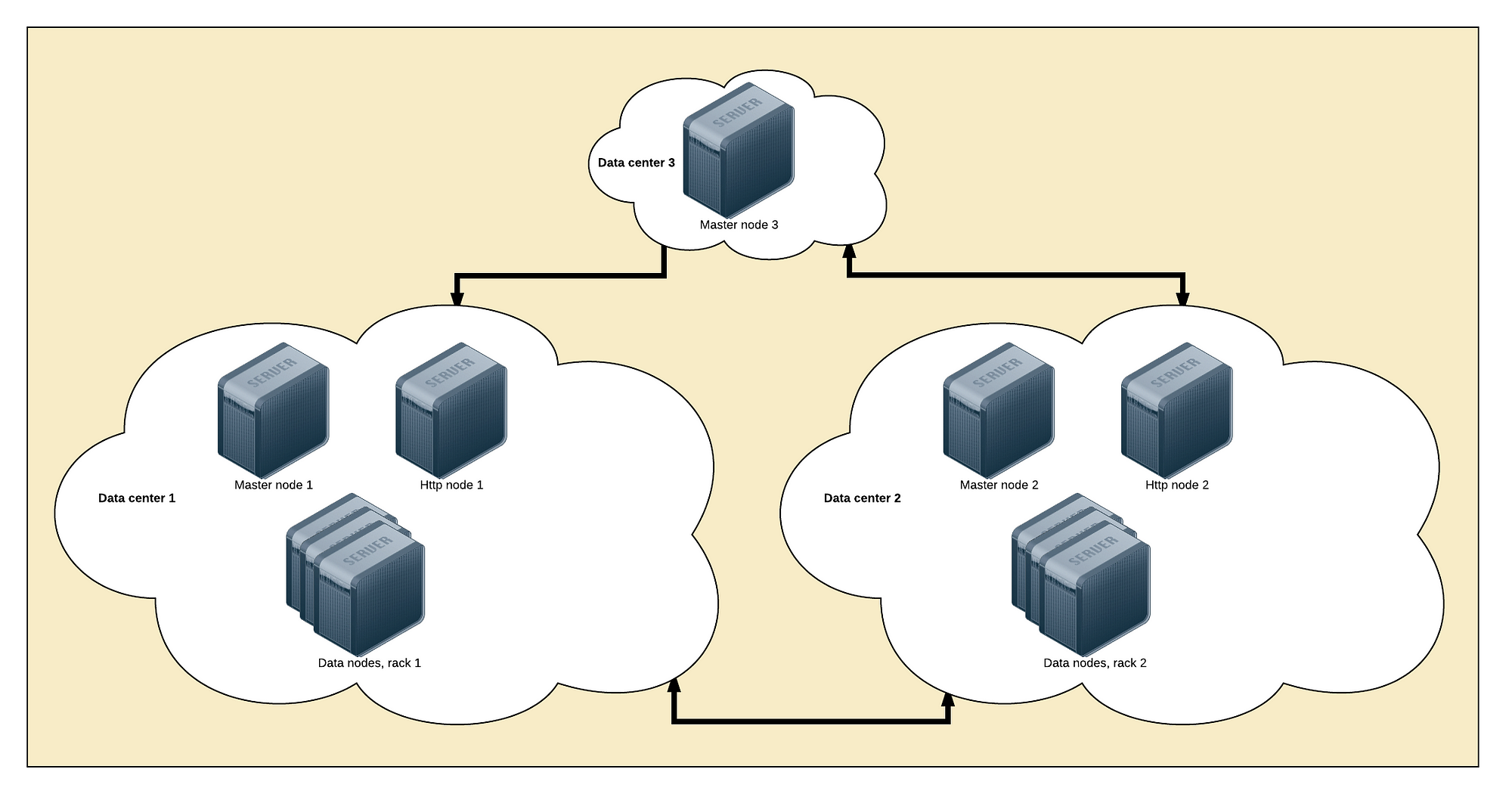
Elasticsearch design for failure
Elasticsearch provides an interesting feature calledshard allocation awareness. It allows to split the primary shards and their replica in separated zones. Allocate nodes within a same data center to a same zone to limit the odds of having your cluster go red.
cluster.routing.allocation.awareness.attributes: "rack_id"
node.attr.rack_id: "dontsmokecrack"
Using rack_id on the http nodes is interesting too, as Elasticsearch will run the queries on the closest neighbours. A query sent to the http node located in the datacenter 1 will more likely run on the same data center data nodes.